Ollama解决了大语言模型运行环境和API调用的问题,Open-WebUI结局了与模型沟通的可视化问题等等。而在当今技术快速发展的时代,大型语言模型(LLM)不仅被广泛应用于各行各业的开发者工具中,也成为了提升业务效率、创造更好用户体验的关键。然而,很多开发者都希望能够在本地部署并体验这些强大的模型,以满足API调用和私有知识库的需求。今天,我将介绍如何通过Docker轻松部署Ollama和Open-WebUI,满足您对本地大语言模型的需求。
经过之前讲解Docker之后,有童鞋好奇那Docker能不能跑一个语言模型玩玩呢,答案是可以的,而且很方便。
又有童鞋好奇NGINX能不能对今天展示的内容做Sub Path的转发呢?一方面呢其实官方还没有支持这么做,硬说能不能把流量都进行拦截并添加上Sub Path?倒也是可以,但其实如果项目方对路由有校验的话,就会前功尽弃。在这个项目中多半是不允许添加Sub Path的。另一方面呢Open-WebUI用了大量的ws,转发起来难度也是很大。
Docker提供了一种方便、高效且一致的环境,使得跨平台部署和管理变得更加简单。通过使用docker-compose,我们可以快速设置Ollama和Open-WebUI,从而让开发者专注于实现业务功能,而无需在环境配置上花费过多的时间。
下面是一个简单的docker-compose.yml文件,它帮助我们通过Docker容器部署Ollama和Open-WebUI。只需简单几步,您就可以启动本地的大语言模型,并通过Web界面进行管理。
version:'3.8'services:ollama:image: ollama/ollama
container_name: ollama
ports:-"11434:11434"volumes:- ./ollama:/root/.ollama
restart: unless-stopped
open-webui:image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
environment:ROOT_PATH:"ollama"OLLAMA_BASE_URL:"http://ollama:11434"ports:-"3020:8080"volumes:- ./open-webui:/app/backend/data
restart: always
depends_on:- ollama
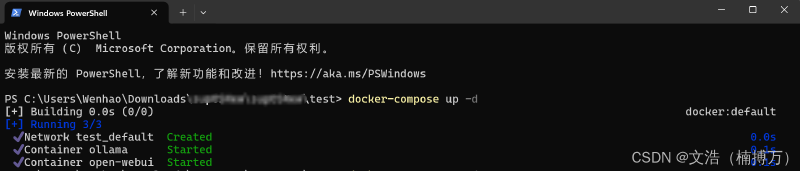
Ollama 服务:
ollama/ollama,并通过端口 11434 进行API服务暴露。./ollama,确保数据的持久化和灵活配置。restart: unless-stopped 使服务在容器崩溃时自动重启,保证高可用性。Open-WebUI 服务:
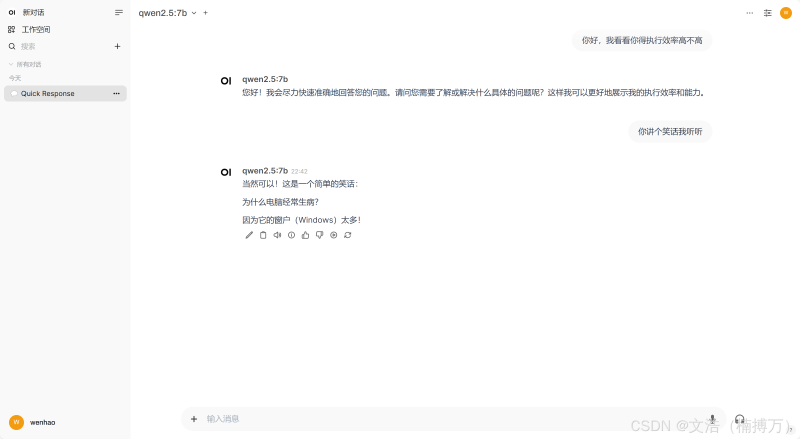
ghcr.io/open-webui/open-webui:main 镜像,部署Web界面,默认监听端口 3020。depends_on 确保Open-WebUI在Ollama启动后才能运行,避免依赖问题。对于中文用户来说,千问模型(Qwen)无疑是一个理想的选择。实践表明,千问模型在处理中文文本时的效果远超其他模型,特别是在自然语言理解和生成方面。通过Ollama的部署,您可以轻松加载千问模型,并进行API调用,极大提升了中文语境下的模型效果。我自己用的是qwen2.5:7b,因为更大的模型我跑不起来。。假如你得配置还不如我呢,那你记得用更小的模型。
API调用需求:
Ollama提供了稳定的API接口,您可以通过本地部署的方式,直接向模型发送请求,获取自然语言处理的结果。无论是文本生成、情感分析,还是其他任务,都可以满足API需求。
私有知识库:
本地部署的Ollama模型不仅能够处理通用任务,还能够结合私有数据进行自定义训练和微调。这样一来,您就可以构建属于自己的私有知识库,增强大语言模型在特定领域的表现。
体验专属的大模型:
对于开发者而言,能够在本地运行一个定制化的大语言模型,无疑是一种极具价值的体验。通过与模型交互,您可以更好地了解其工作原理并优化应用,提升开发效率。
通过简单的Docker部署,您不仅能够快速搭建Ollama和Open-WebUI,还能够体验到私有化部署大语言模型的强大功能。对于中文用户,千问模型提供了更好的本地化体验,而本地部署更是保证了数据隐私和模型性能。无论是API调用,还是私有知识库的建设,本地化的解决方案都将大大提升您的开发体验。
立即尝试并在本地部署,解锁更多关于大语言模型的潜力,打造属于您自己的智能应用!
通过上述内容,你就已经基本理解了这个方法,基础用法我也都有展示。如果你能融会贯通,我相信你会很强
Best
Wenhao (楠博万)
















提示:请勿发布广告垃圾评论,否则封号处理!!