🔥博客主页: 【小扳_-CSDN博客】
❤感谢大家点赞👍收藏⭐评论✍


文章目录
1.0 GEO 数据结构的基本用法
1.1 使用 GEO 导入数据
1.2 使用 GEO 实现查找附近店铺功能
2.0 BitMap 基本用法
2.1 使用 BitMap 实现签到功能
2.2 统计连续签到功能
3.0 HyperLogLog 基本用法
3.1 测试使用 HyperLogLog 统计数据
GEO 就是 Geolocation 的简写形式,代表地理坐标。Redis 在 3.2 版本中加入了对 GEO 的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据。常见的命名有:
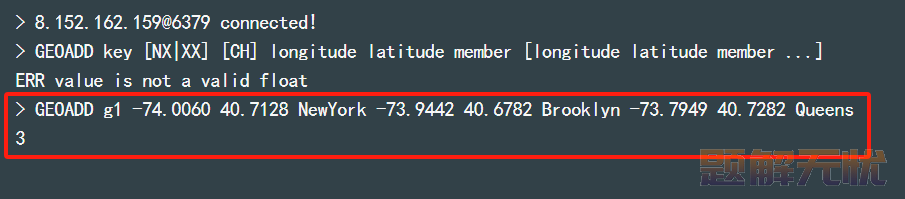
1)GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)。
GEOADD key [NX|XX] [CH] longitude latitude member [longitude latitude member ...]
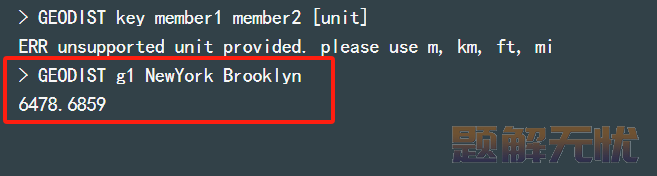
2)GEODIST:计算指定的两个点之间的距离并返回。
GEODIST key member1 member2 [unit]
需要注意的是:距离默认是以 m 为单位。
3)GEOHASH:将指定的 member 的坐标转为 hash 字符串形式并返回。
GEOHASH key member [member ...]
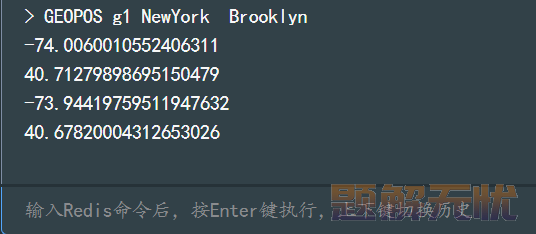
4)GEOPOS:返回指定 member 的坐标。
GEOPOS key member [member ...]
5)GEOSEARCH:在指定范围内搜索 member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。
GEOSEARCH key longitude latitude radius [WITHDIST]
6)GEOSEARCHSTORE:与 GEOSEARCH 功能一致,不过可以把结果存储到一个指定的 key 。
GEOSEARCHSTORE destination key longitude latitude radius [WITHDIST] [WITHCOORD] [WITHHASH] [SORTBY field [ASC|DESC]] [COUNT count]
具体参数:
destination: 结果将被存储的目标键。
key: 包含地理位置数据的键。
longitude: 搜索中心的经度。
latitude: 搜索中心的纬度。
radius: 搜索半径,可以是距离单位(如 km 或 m)。
WITHDIST: 可选参数,返回每个结果与中心点的距离。
WITHCOORD: 可选参数,返回每个结果的经纬度坐标。
WITHHASH: 可选参数,返回每个结果的地理哈希值。
SORTBY field: 可选参数,按指定字段排序(如距离)。
COUNT count: 可选参数,限制返回的结果数量。
一般来说,用户在查询信息的时候,通过分类来进行的查询用户想要的结果,比如说:用户根据美食、KTV、酒店等等不同的店铺分类来进行选择。
因此,通过设置 key 为分类 ID 将店铺分类。
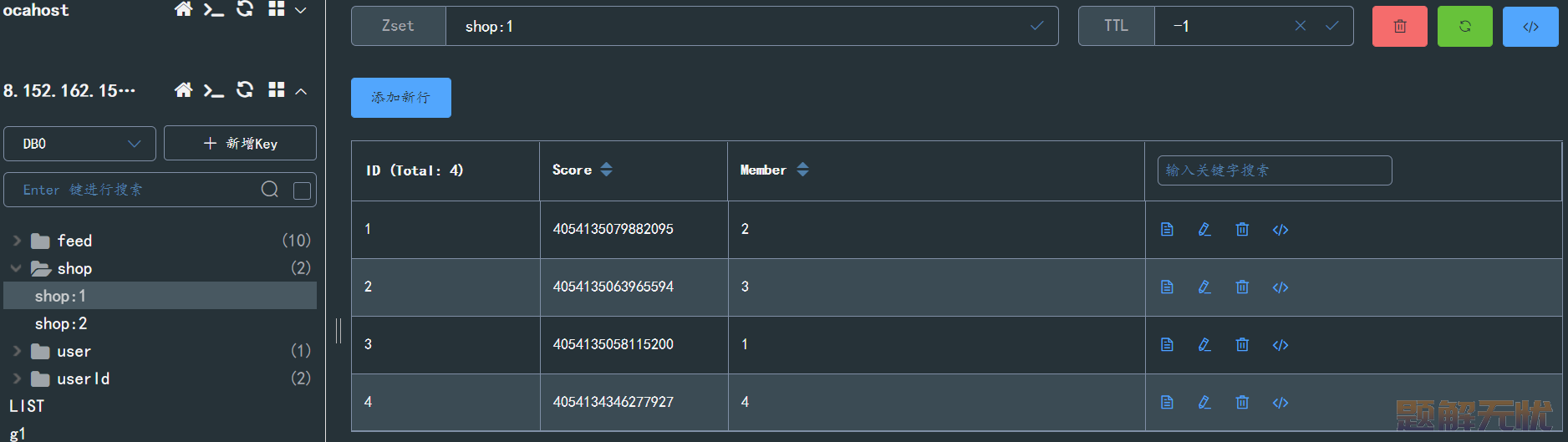
GEO 底层的数据结构是 SortedSet 实现的,将 Score 设置为通过经纬度算出来的数据,而 value 设置为 member ,该值一般是表示店铺的信息,也就是可以将其设置为店铺 ID 。
具体思路:
将存放在数据库中的店铺信息缓存到 Redis 中:
将数据库中的店铺信息全部查询出来,解决根据店铺的分类,将店铺进行分类,使用 map 来接收:key 为 typeId,value 为 shop 店铺的具体信息。最后就可以将数据存放到缓存中。
代码如下:
@Autowired StringRedisTemplate stringRedisTemplate; @Autowired ShopMapper shopMapper; @Test void text1(){ //先获取店铺信息 List<Shop> list = shopMapper.getList(); //将店铺进行分类 Map<Integer, List<Shop>> map = list.stream().collect(Collectors.groupingBy(Shop::getTypeId)); //接着将信息放入到Redis中 for (Map.Entry<Integer, List<Shop>> entry : map.entrySet()) { //店铺ID Integer id = entry.getKey(); String key = "shop:"+id; //当前类的店铺 List<Shop> value = entry.getValue(); List<RedisGeoCommands.GeoLocation<String>> locations = new ArrayList<>(value.size()); for (Shop shop : value) { locations.add(new RedisGeoCommands.GeoLocation<>(shop.getId().toString(), new Point(shop.getX(), shop.getY()))); } stringRedisTemplate.opsForGeo().add(key,locations); } }运行结果:
需求:根据指定的经纬度、页码、店铺类型参数来进行查找店铺信息。
具体思路:
对于店铺类型可以根据店铺分类 ID 来进行过滤,当前页码 current 可以求出 from 起始开始的地方和 end 结尾的地方:from = (current - 1) * size ,end = current * size ,其中 size 是指定每页的最大数量。
代码如下:
@Test void text2(){ List<Shop> shops = getShops(2, 120.149192, 30.316078,1); System.out.println(shops); } private List<Shop> getShops(int current, double x, double y,int typeId){ //根据分类ID来查找 String key = "shop:"+ typeId; //起始地址 int from = (current - 1) * 2; //最终地址 int end = current * 2; //使用范围查找5公里以内的店铺,且进行分页查询 GeoResults<RedisGeoCommands.GeoLocation<String>> results = stringRedisTemplate.opsForGeo().search( key, GeoReference.fromCoordinate(new Point(x, y)), new Distance(5000), RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end)); if (results == null){ return null; } //获取符合条件的店铺列表 List<GeoResult<RedisGeoCommands.GeoLocation<String>>> content = results.getContent(); if (content.size() <= from){ return null; } //跳过前 from 个店铺,这就可以获取到 from - end 个店铺的信息 List<GeoResult<RedisGeoCommands.GeoLocation<String>>> collect = content.stream().skip(from).toList(); List<Integer> id = new ArrayList<>(collect.size()); Map<Integer,Double> shopMap = new HashMap<>(collect.size()); for (GeoResult<RedisGeoCommands.GeoLocation<String>> result : collect) { //拿到了店铺ID id.add(Integer.valueOf(result.getContent().getName())); //再拿到店铺距离 Distance distance = result.getDistance(); shopMap.put(Integer.valueOf(result.getContent().getName()), distance.getValue()); } //根据店铺ID来查询具体的店铺信息 List<Shop> list = shopMapper.getShopList(id); for (Shop shop : list) { shop.setDistance(shopMap.get(shop.getId())); } return list; }
常见的命令:
1)SETBIT:向指定位置(offset)存入一个 0 或者 1。
SETBIT key offset value
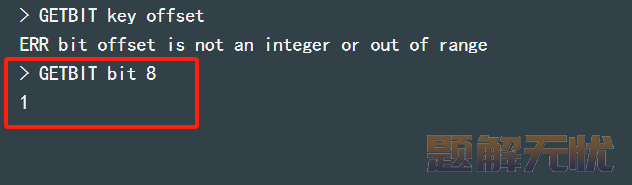
2)GETBIT:获取指定位置(offset)的 bit 值。
GETBIT key offset
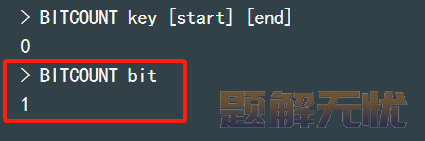
3)BITCOUNT:统计 BitMap 中值为 1 的 bit 位的数量。
BITCOUNT key [start] [end]
4)BITFIELD:操作(查询、修改、自增)BitMap 中 bit 数组中指定位置(offset)的值。
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW overflow]
offset:从第几个开始
type:u1 无符号查询,查询 1 个、i3 有符号查询,查询 3 个。
5)BITOP:将多个 BitMap 的结果做位运算。
BITOP operation destkey key [key ...]
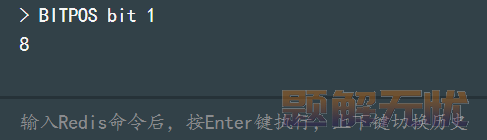
6)BITPOS:查找 bit 数组中指定范围内第一个 0 或者 1 出现的位置。
BITPOS key bit [start] [end]
把每一个 bit 对应当月的每一天,形成了映射关系。用 0 和 1 表示业务状态,这种思路就称为位图。 Redis 中是利用 string 类型数据结构实现 BitMap ,因此最大上限是 512 M,转换为 bit 则是 2^32 个 bit 位。
代码实现:
@Test void text3(){ //用户1 sign(1); //用户2 sign(2); //用户3 sign(3); } private void sign(Integer userId){ //获取当前时间 LocalDateTime now = LocalDateTime.now(); String date = now.format(DateTimeFormatter.ofPattern("yyyyMM:")); String key = "sign:"+ date +userId; //当前天数 stringRedisTemplate.opsForValue().setBit(key,now.getDayOfMonth()-1,true); }运行结果:
从最后一天开始往前累计直到遇到 0 的时候,统计出连续签到功能。先使用 BITFIELD 命令获取从本月 0 到当前月中的第 x 天的十进制数,再将该十进制数循环跟 1 进行与运算,当结果不为 0 的时候,累计次数;当结果为 0 的时候,跳出循环。
代码如下:
@Test void text4(){ coiledSign(1); } private void coiledSign(Integer userId){ //获取当前时间 LocalDateTime now = LocalDateTime.now(); String date = now.format(DateTimeFormatter.ofPattern("yyyyMM:")); String key = "sign:"+ date +userId; List<Long> list = stringRedisTemplate.opsForValue().bitField(key, BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(now.getDayOfMonth())).valueAt(0)); if (list == null || list.isEmpty()){ return; } //拿到列表中第一个元素 Long aLong = list.get(0); if (aLong == null || aLong == 0){ return; } int count = 0; while (true){ if ((aLong & 1) == 0){ break; }else { count++; } aLong >>>= 1; } System.out.println("当前用户连续签到了:"+count+"次"); }运行结果:
1)UV:全称 Unique Visitor,也叫独立访客量,是指通过互联网访问,浏览这个网页的自然人。1 天内同一个用户多次访问该网站,只记录 1 次。
2)PV:全称 Page View,也叫页面访问量或点击量,用户没访问网站的一个页面,记录 1 次 PV,用户多次打开页面,则记录多次 PV。往往用来衡量网站的流量。
UV 统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到 Redis 中,数据量会非常恐怖。
而 HyperLogLog 是从 LogLog 算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。
Redis 中的 HLL 是基于 string 结构实现的,单个 HLL 的内存永远小于 16 kb,内存占用低的令人发指!作为代价,其测量结果是概率性的,有小于 0.81% 的误差。不过对于 UV 统计来说,这完全可以忽略。
常见的命令:
1)PFADD:在 key 中添加数据
PFADD key element [element ...]
2)PFCOUNT:统计 key 中的数据量
PFCOUNT key [key ...]
3)PFMERGE:合并两个 key 中的数据量
PFMERGE destkey sourcekey [sourcekey ...]
使用起来也很简单。每当用户来访问该网站的时候,都将当前用户 ID 都添加到 key 中,key 既可以设置为以天为单位、以月为单位等,如果用户 ID 重复来访问该网站,那么 HyperLogLog 会自动帮我们做了处理,完美符合 UV 的规则,因此使用 HyperLogLog 实现 UV 是非常合适的。
代码如下:
@Test void text5(){ //添加数据 LocalDateTime now = LocalDateTime.now(); String format = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd")); String key = "UV:"+ format; for (int i = 0; i < 5000; i++) { stringRedisTemplate.opsForHyperLogLog().add(key,"user"+i); } } @Test void text6(){ //进行统计 LocalDateTime now = LocalDateTime.now(); String format = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd")); String key = "UV:"+ format; Long size = stringRedisTemplate.opsForHyperLogLog().size(key); System.out.println(size); }




















提示:请勿发布广告垃圾评论,否则封号处理!!