
最近发现了一款工具大语言语料处理神器-MinerU, 非常适合在RAG等应用场景中使用, 开源免费
MinerU其中的一个功能是将 PDF 转化为 markdown 格式的工具, 对PDF文档提取的效果目前是市面上效果比较好的, 最新的版本还支持了PDF中表格的识别
MinerU 官方仓库: https://github.com/opendatalab/MinerU
MinerU 版本更新记录
doclayout_yolo 模型,在相近解析效果情况下比原方案提速10倍以上,可通过配置文件与 layoutlmv3 自由切换unimernet 0.2.1,在提升公式解析准确率的同时,大幅降低显存需求PDF-Extract-Kit 1.0 更换仓库,需要重新下载模型,步骤详见 如何下载模型装环境相对麻烦, 为此我制作了Windows系统的环境一键整合包, 下面就介绍下这个环境一键包的使用
MinerU环境一键整合包下载地址
链接: https://pan.quark.cn/s/f57a7b0f0232
搞不定环境的可以用这个 里面有使用说明文档(在Windows11正常运行, 其他系统未测, 如有问题, 可以留言)
使用很简单, 无需复杂的安装部署, 下载后解压即可使用, 已经包含了模型, 整合了Python单独的环境以及所需的包, 独立不干扰系统环境, 小白也可以用, 也可以用于开发
使用之前需要安装里面的cuda, 安装cuda的教程自行百度, 如果已经安装请忽略
如果之前安装有cuda这个报错的, 可以卸载之前的cuda, 安装里边的cuda11.8版本
解压后即可运行
但要注意: 解压的路径最好不要带中文, 或者带空格的文件夹, 以免导致各种疑难杂症
点击运行Gradio简易版界面.bat, 运行Gradio简易版界面, 页数限制改成了100000
和 https://www.modelscope.cn/studios/OpenDataLab/MinerU 功能一样
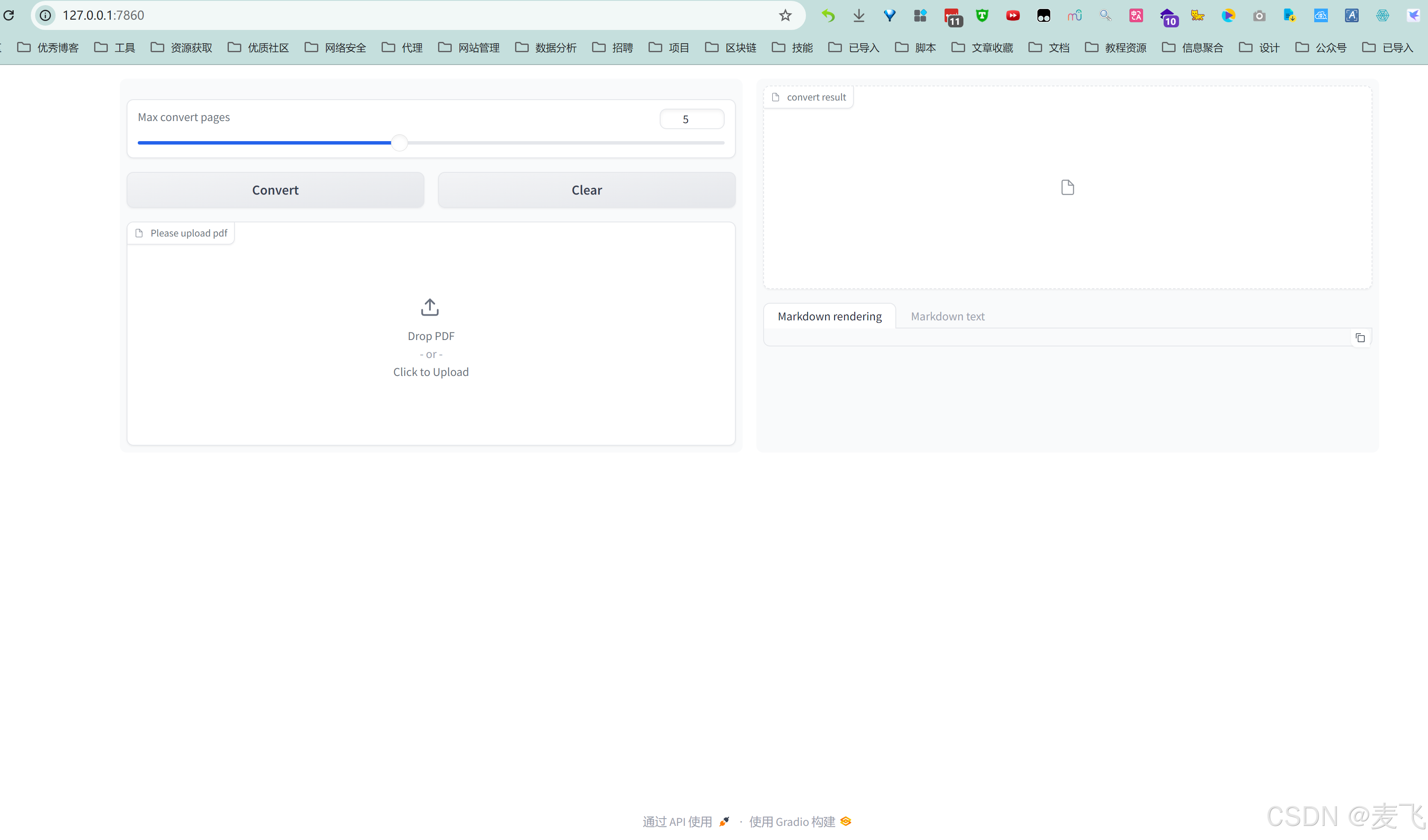
点击Gradio完整版界面.bat, 运行Gradio完整版界面, 把页数限制改成了100000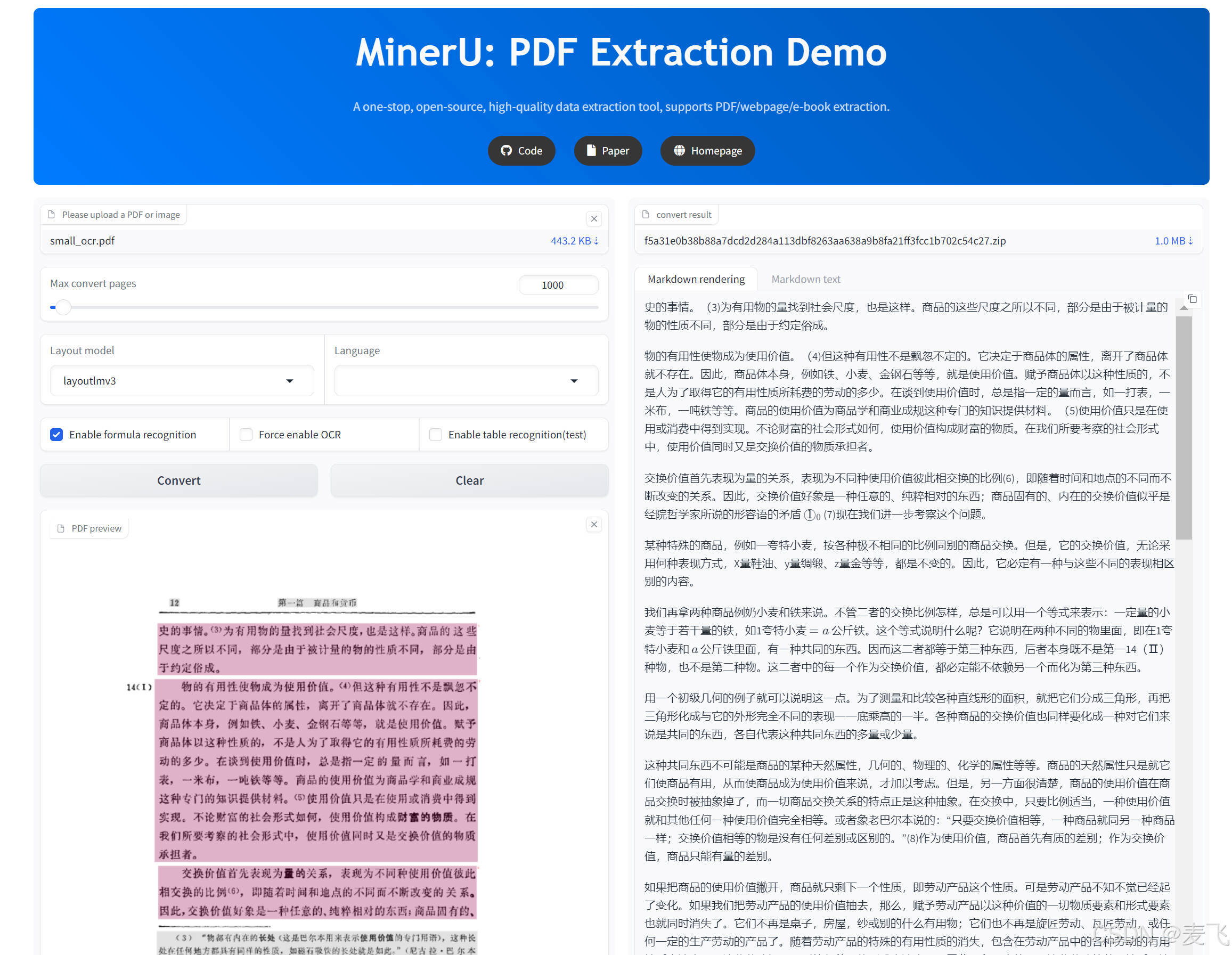
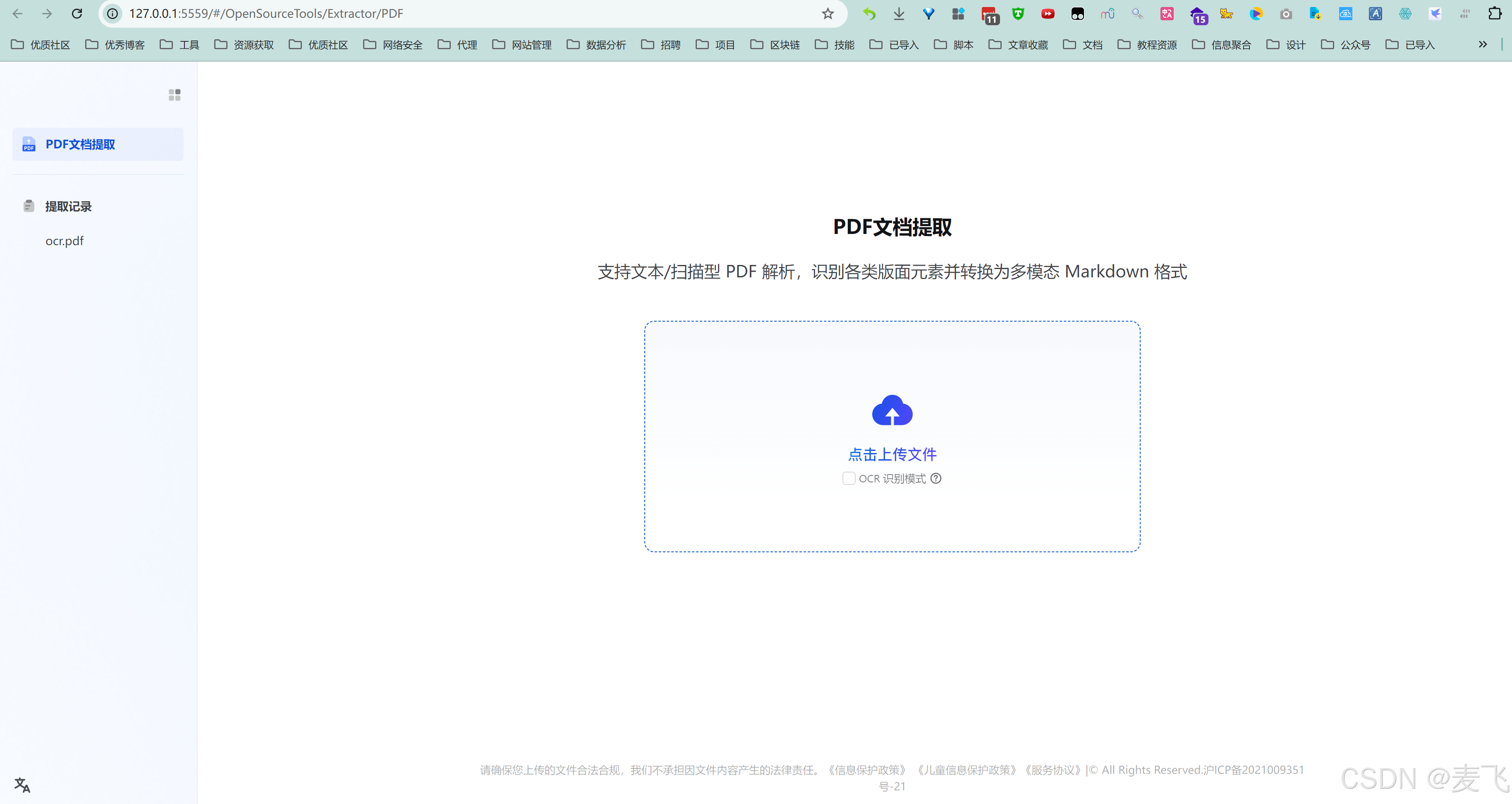
点击运行web版.bat 运行web网页版
功能和 https://opendatalab.com/OpenSourceTools/Extractor/PDF 一样
目录python为嵌入版的环境, 已经安装了所有依赖
想深入使用, 可以配合官方说明文档使用, 下面是一些简要说明
magic-pdf.json
为配置文件, 使用的方式和官方一样
small_ocr.pdf
为测试用pdf文件
app.py
为gradio网页在线版 和 https://www.modelscope.cn/studios/OpenDataLab/MinerU 功能一样
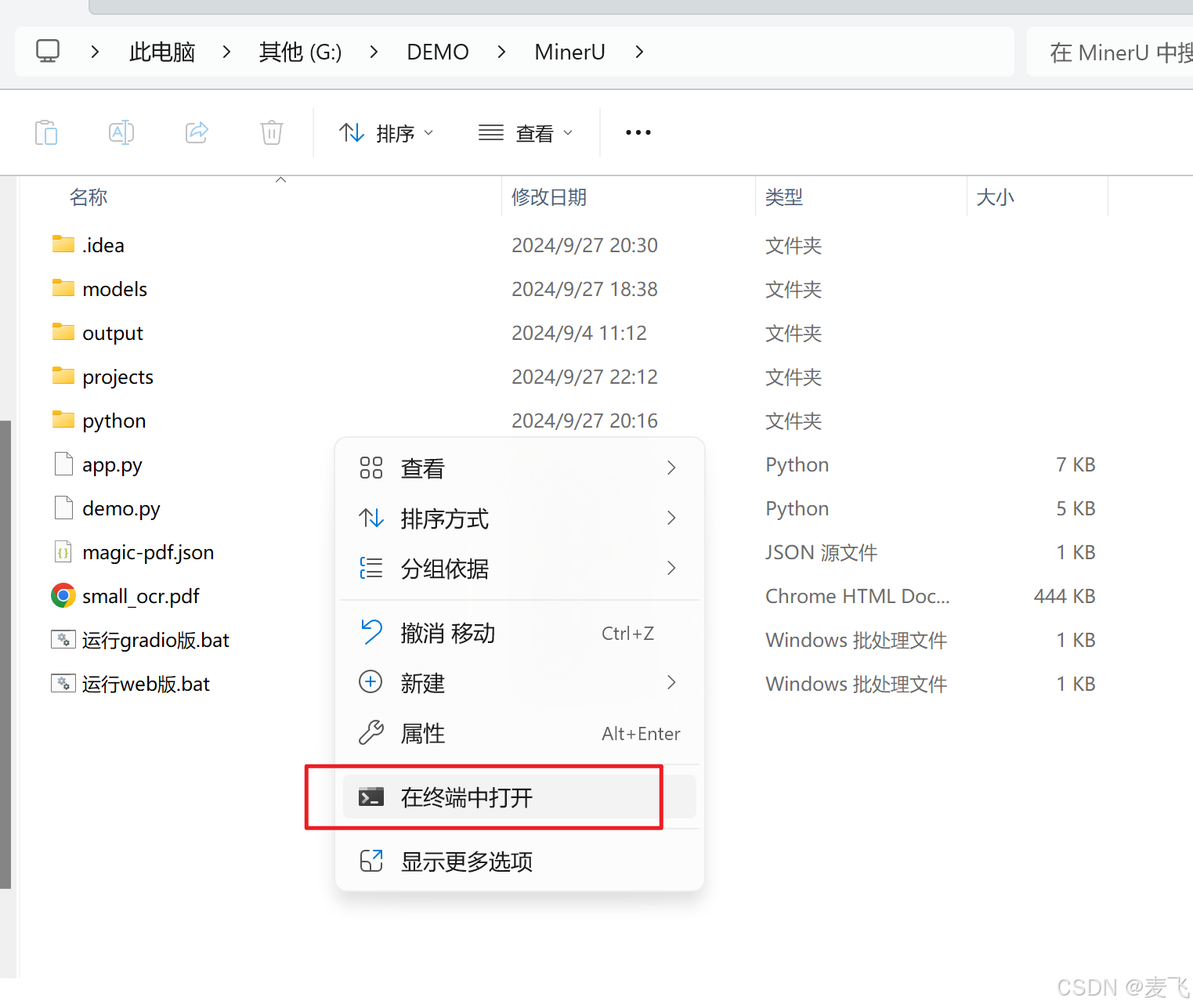
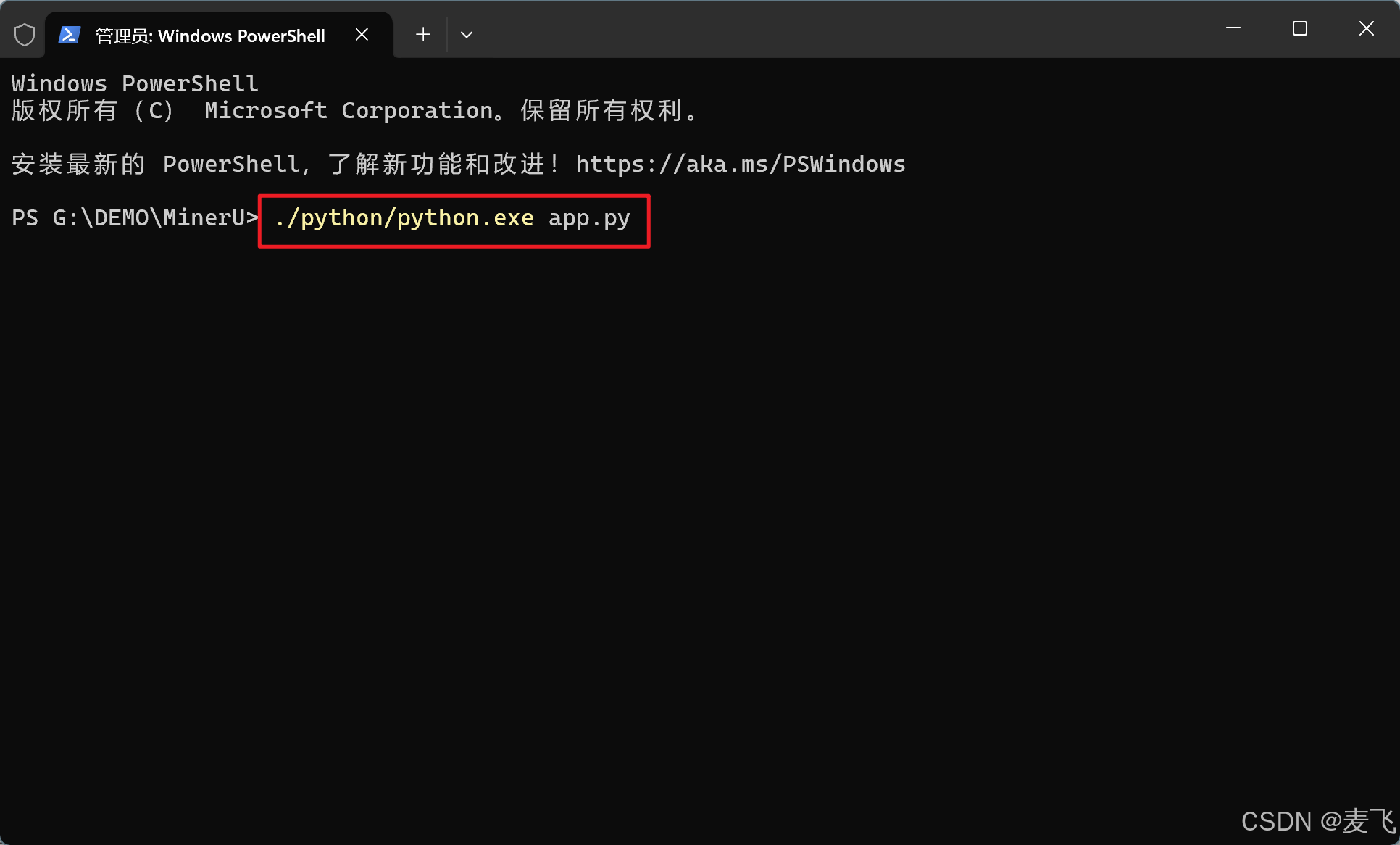
运行方式, 在MinerU目录右键启动cmd, 或者启动cmd切换到MinerU目录, 运行下列命令
./python/python.exe app.py
demo.py
为官方运行示例
运行方式, 在MinerU目录右键启动cmd, 或者启动cmd切换到MinerU目录, 运行下列命令
./python/python.exe demo.py
如果要对Python环境里边的包进行操作的, 将原有的
pip install xxx
换成
./python/python.exe -m pip install xxx
就可以了
官方的命令使用
magic-pdf -p {some_pdf} -o {some_output_dir} -m auto
在MinerU目录右键启动cmd, 或者启动cmd切换到MinerU目录, 运行下列命令
./python/Scripts/magic-pdf.exe -p {some_pdf} -o {some_output_dir} -m auto
例如
./python/Scripts/magic-pdf.exe -p small_ocr.pdf
或者路径填magic-pdf.exe所在的绝对路径, 例如
G:/MinerU/python/Scripts/magic-pdf.exe -p small_ocr.pdf
如果包损坏了, 可以通过下面两个命令进行重新下载更新
./python/python.exe -m pip install -U magic-pdf[full]
./python/python.exe -m pip install -r ./projects/web_demo/requirements.txt
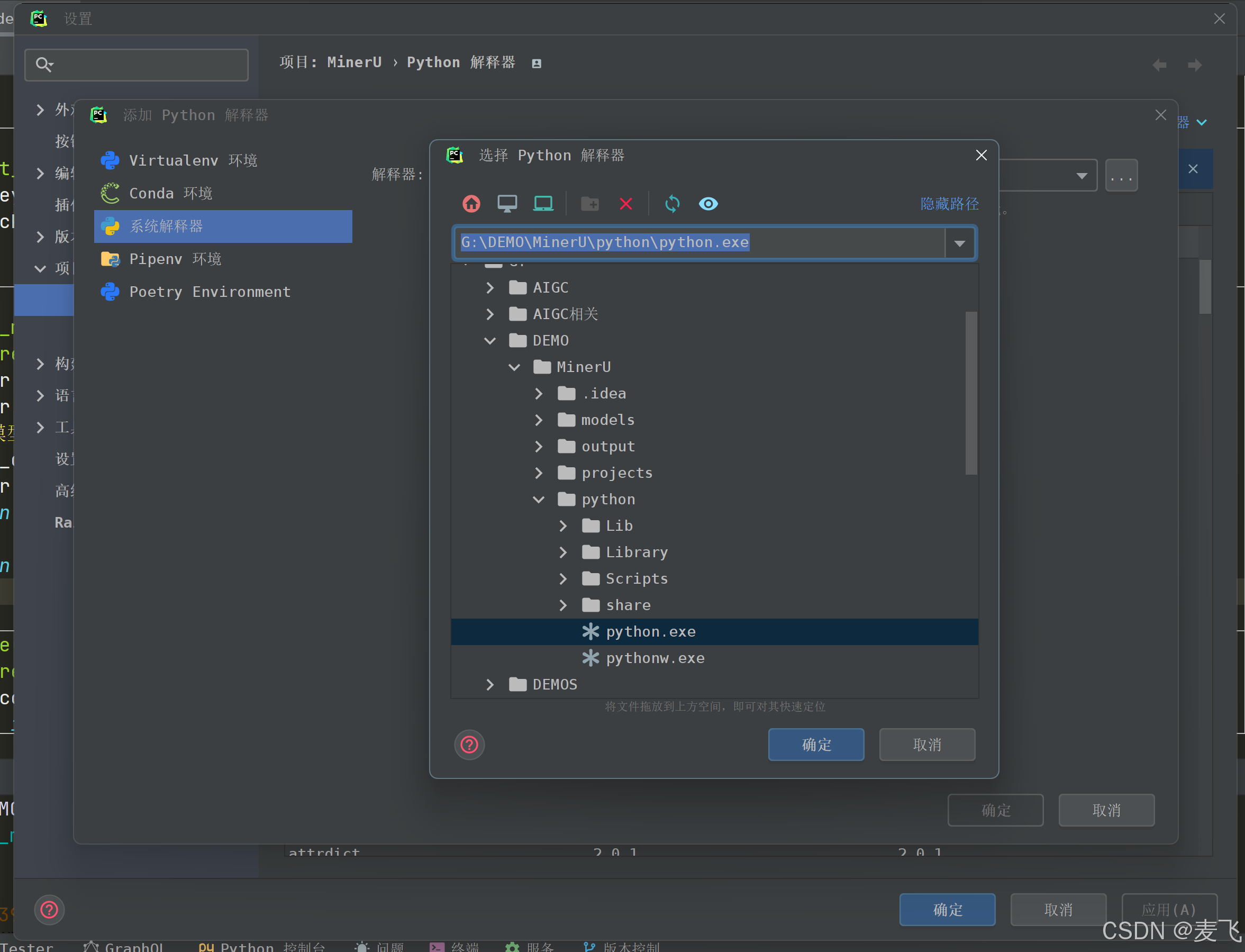
在pycharm里环境变量填python/python.exe所在目录
更新命令
./python/python.exe -m pip install --upgrade magic-pdf
更新后需修改文件
python/Lib/site-packages/magic_pdf/libs/config_reader.py
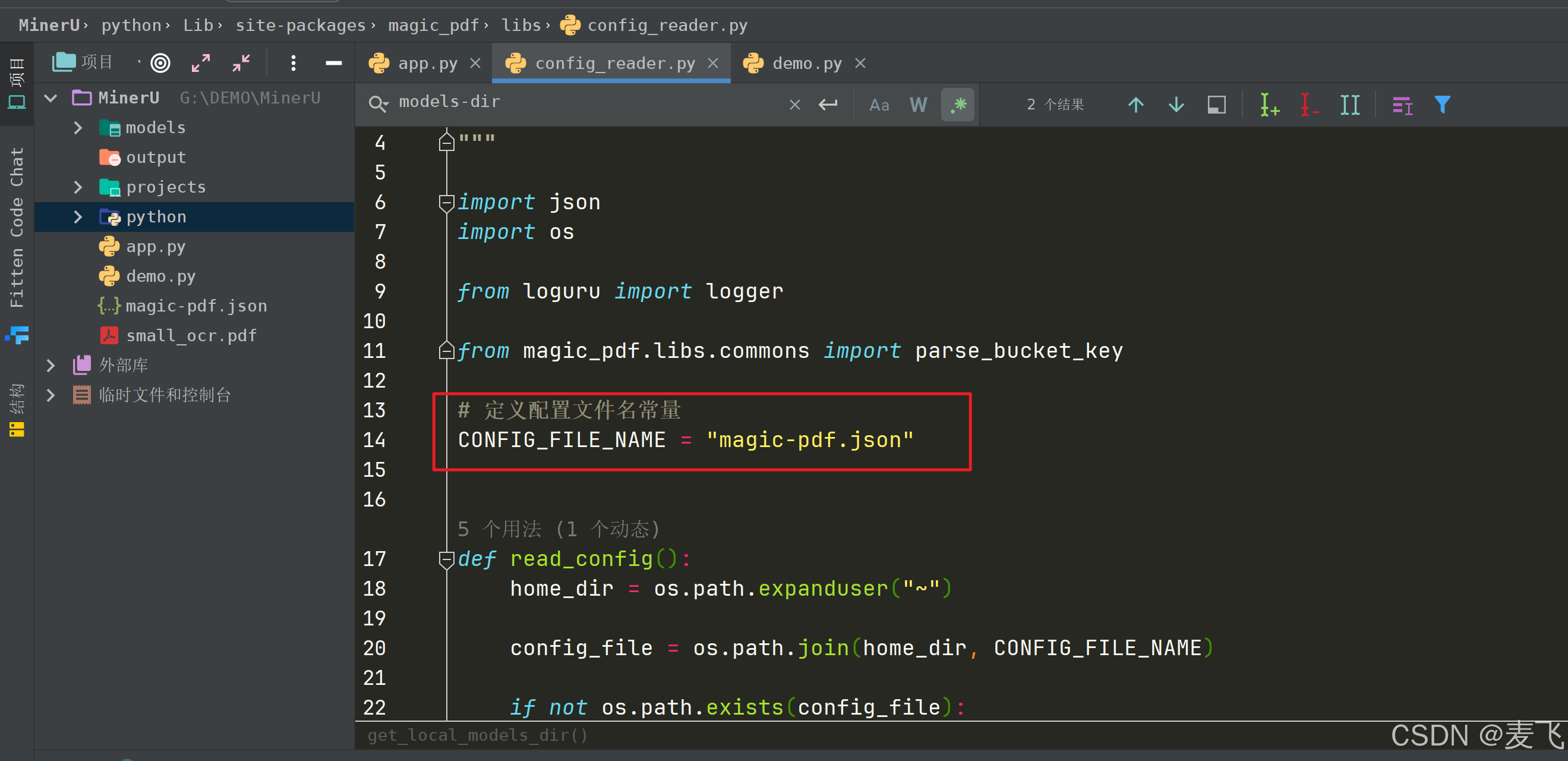
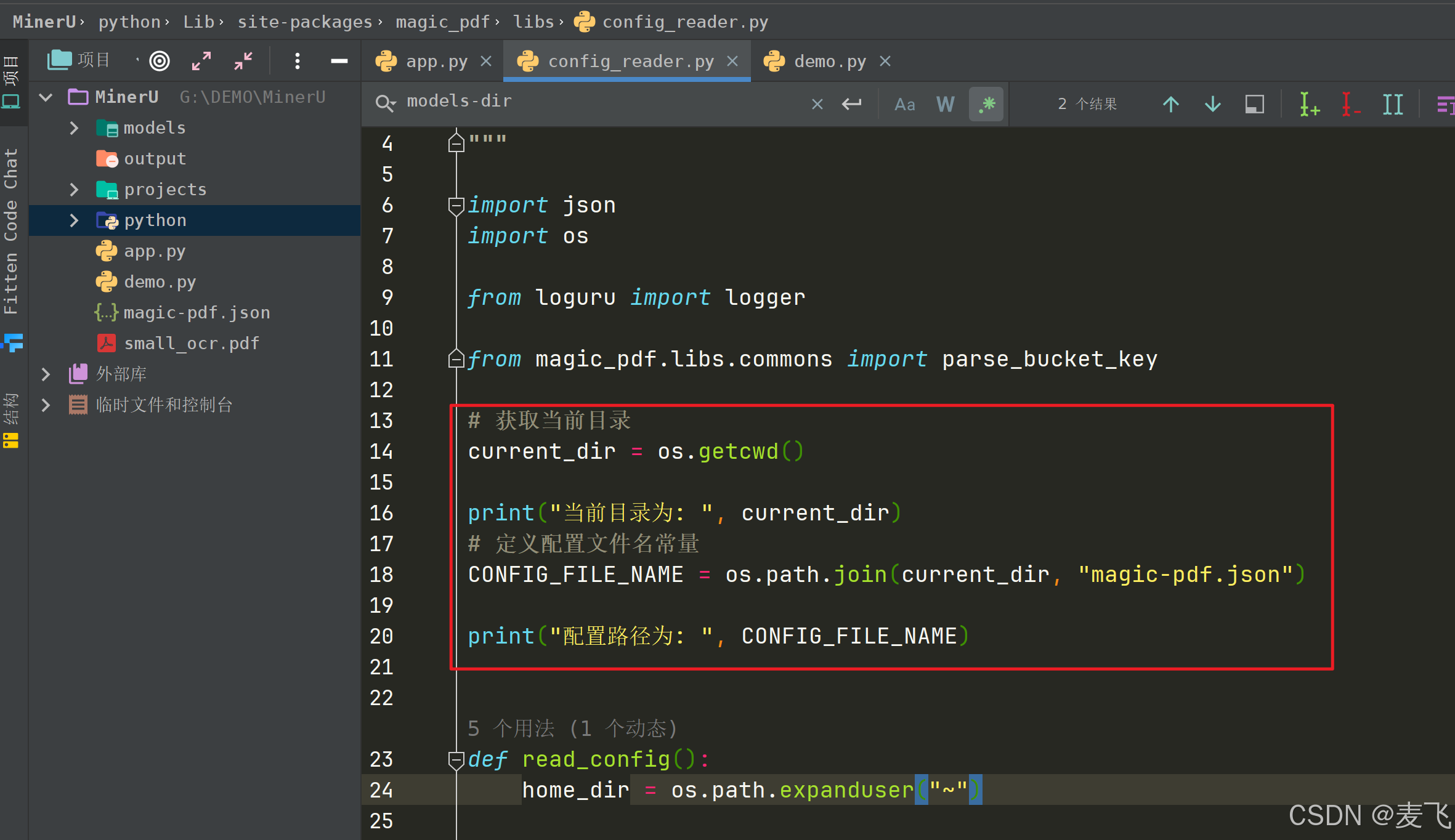
把13-14行红框替换为如下代码
# 获取当前目录
current_dir = os.getcwd()print("当前目录为: ", current_dir)# 定义配置文件名常量
CONFIG_FILE_NAME = os.path.join(current_dir,"magic-pdf.json")print("配置路径为: ", CONFIG_FILE_NAME)
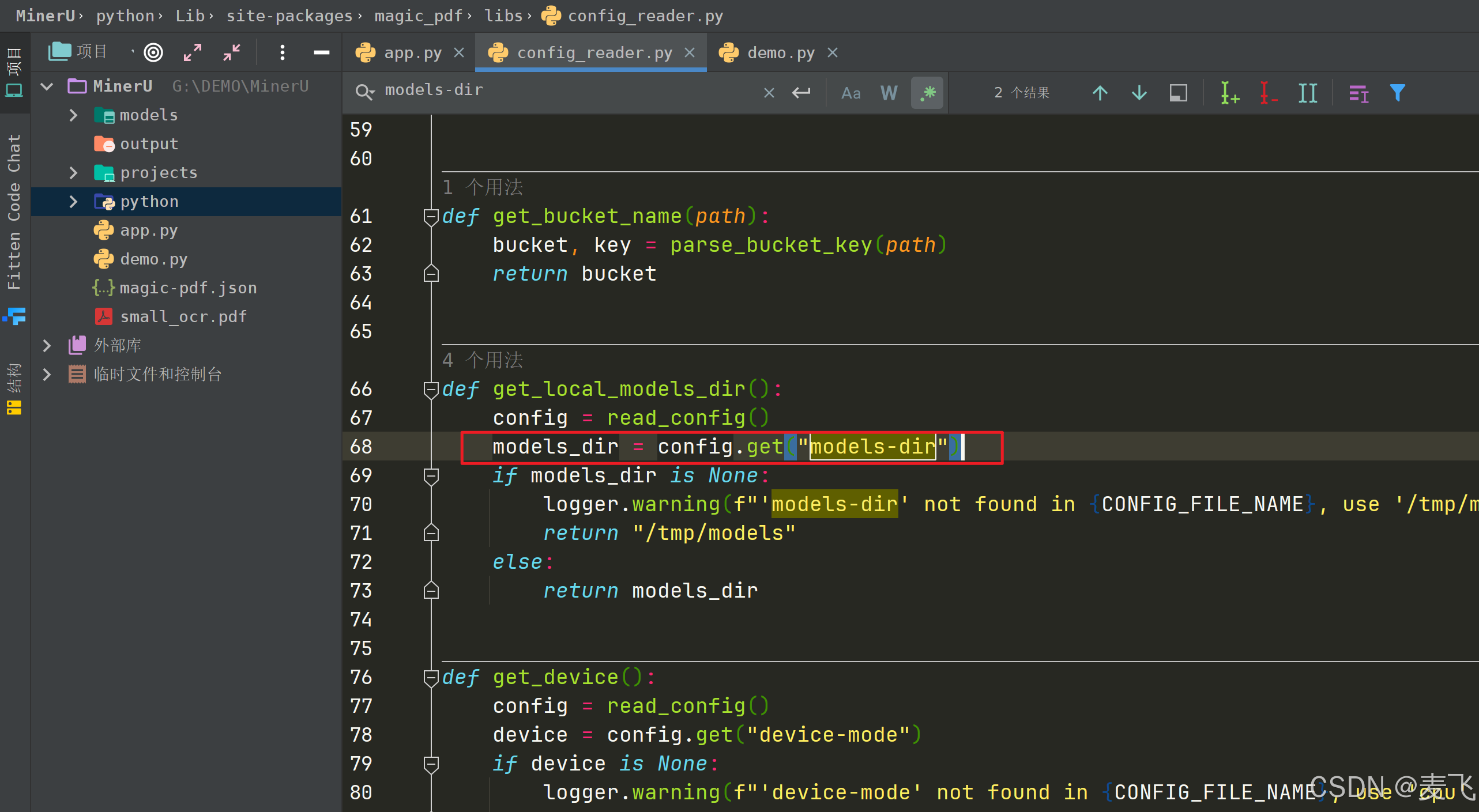
在69行最用红框处插入如下代码
models_dir = os.path.join(current_dir, models_dir)print(f"模型目录为: {models_dir}")
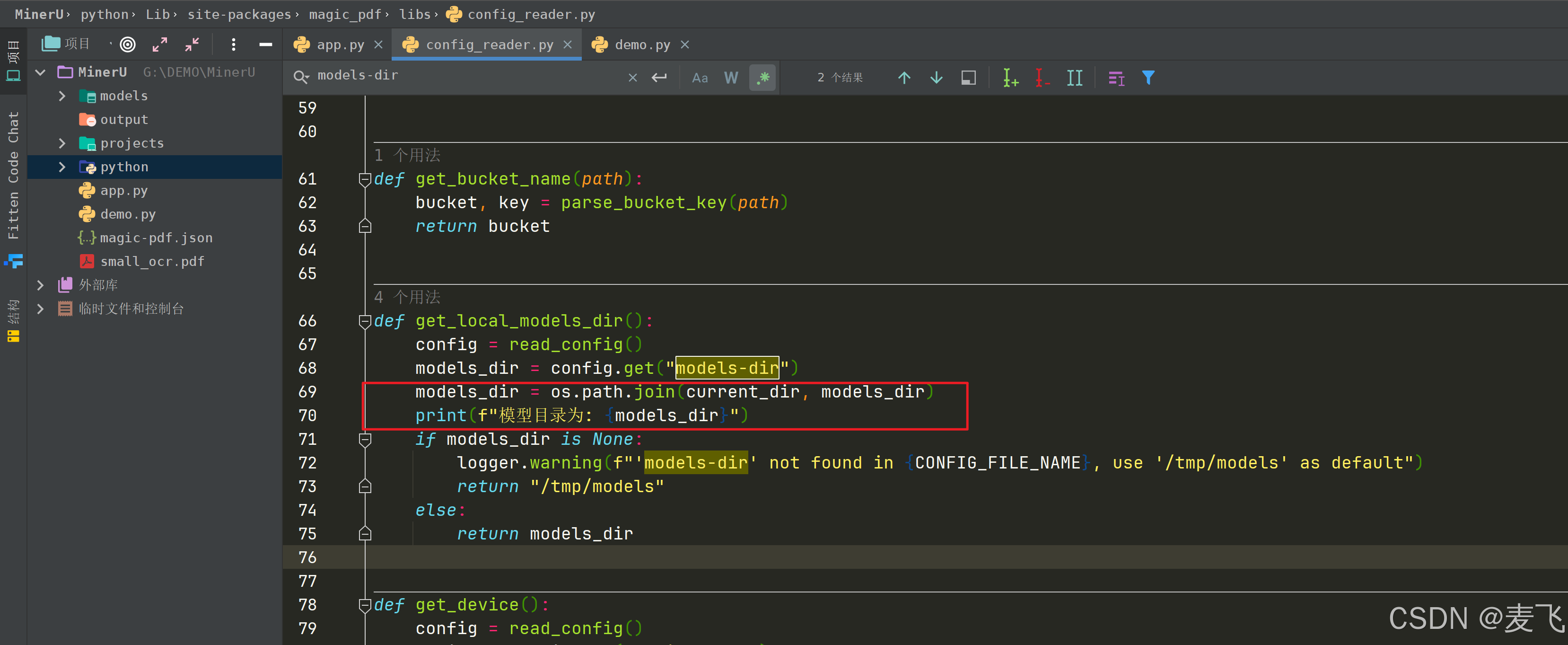
这样路径才不会报错
















提示:请勿发布广告垃圾评论,否则封号处理!!